
Clever management of website crawling and indexing is the ultimate skill for webmasters and SEO specialists alike. And there are a number of ways to attract search bots to a site or restrict access to it. In this article, we’ll explore how to do it all with the help of the robots.txt file.

What is robots.txt?
Robots.txt is a text file that contains crawling recommendations for the bots. It is part of the robots exclusion protocol (REP), a group of web standards that regulates how bots view, access, index, and present content to the users. The file contains instructions (directives) through which you can restrict the bots from accessing specific sections, pages and files or specify the Sitemap address.
Most major search engines such as Google, Bing, and Yahoo start crawling websites by checking the robots.txt file and following the prescribed recommendations.
Why is robots.txt important?
The majority of websites geared mainly toward Google may not need the robots.txt file. This is due to the fact that Google considers them purely as recommendations, with Googlebot usually finding and indexing all important pages regardless.

Therefore if this file isn’t created, it will not be a critical mistake. In that case, the search bots will assume that there are no restrictions and they can scan away freely.
Despite that, there are 3 main reasons why you should actually use robots.txt:
- It optimizes the crawl budget. If you have a large site, it is important that search bots crawl all the important pages. However, sometimes crawlers find and index auxiliary pages, such as filter pages, while ignoring the main ones. You can address that situation by blocking the non-essential pages through robots.txt.
- It hides non-public pages. Not everything on your site needs to be indexed. One good example is the authorization or testing pages. While objectively they should exist, you can block them with robots.txt, keeping them out of search engine index and out of the reach of random people.
- It prevents the indexing of images and PDFs. There are a couple of ways to prevent the indexing of pages without using robots.txt. However, none of them work great when it comes to media files. So if you don’t want search engines to index images or PDFs on your site, the easiest way is to block them through robots.txt.
File requirements
For search bots to correctly handle the file, you need to follow the rules:
- It has to be located in the site’s root directory.
- It has to be named "robots.txt" and be available at https://yoursite.com/robots.txt.
- Only one such file per site is allowed.
- UTF-8 encoding.
Robots.txt syntax
Directives
The robots.txt file includes two main directives — User-agent and Disallow, but there are also additional ones, such as Allow and Sitemap. Let’s take a closer look at what information they convey and how to add it properly.

User-agent
This is a mandatory directive. It defines which search bots the rules apply to.
There are many robots that can scan websites, with search engine bots being the most common ones.
Some of the Google bots include:
- Googlebot;
- Googlebot-Image;
- Googlebot-News.
You can find the complete User-Agent list used by search engines in their documentation. For Google, it looks like this.
Be aware that some crawlers can have more than one user agent token. For the rule to be applied correctly, it is important that the marker corresponds to only one crawler.
To address a particular bot, such as Googlebot Image, you need to enter its name in the User-agent line:
If you want to apply the rules to all the bots, use the asterisk (*). Example:
Disallow
This indicates a page and directory of the root domain that the specified User-agent cannot scan. Use the Disallow directive to deny access to the entire site, directory, or a specific page.
1. If you want to restrict access to the entire site, add a slash (/). For example, to prohibit all robots from accessing the entire site, you must indicate the following in your robots.txt file:
You might need to use such a combination if your site is in the early stages of development when you want it to appear in search results fully completed.
2. To restrict access to the contents of a directory, use its name followed by a slash. For example, to prevent all bots from accessing the blog directory, you need to write the following in the file:
3. If you need to close a specific page, you should specify its URL without the host. For example, to close the https://yoursite.com/blog/website.html page, you should write the following in your file:
Allow
This indicates the page and directory of the root domain that can be scanned by the specified User-agent and is considered to be an optional directive. If no restriction is specified, then by default, bots can scan the site unhindered. Thus the following is entirely optional:
However, you will need to use this directive to override the restriction of the Disallow directive. Basically, it can be used to allow the scanning of a part of a restricted section or site. For example, if you want to restrict access to all the pages in the /blog/ directory except for https://yoursite.com/blog/website.html, you will need to specify the following:
Sitemap
This optional directive serves to specify the location of the site’s Sitemap.xml file. If your site has multiple Sitemaps, you can specify them all.
Make sure to indicate the complete URL of the Sitemap.xml file. The directive can be placed anywhere in the file, but often it is done at the very end. The robots.txt file with links to several Sitemap.xml would look like this:
Special characters $, *, /, #
1. The asterisk character (*) stands for any sequence of characters. In the example below, using an asterisk will deny access to all URLs containing the word website:
This special character is added at the end of each line by default. So the two examples below would essentially mean the same thing:
2. To override the asterisk (*), you must include the dollar sign ($) character at the end of the rule.
For example, to disallow access to /website but allow it to /website.html, you can write:
3. Slash is a basic character usually found in every Allow and Disallow directive. With it, you can deny access to the /blog/ folder and its contents or all pages that begin with /blog.
Example of a directive denying access to the entire /blog/ category:
Example of a directive denying access to all the pages beginning with /blog:
4. The number sign (#) is used to add comments inside the file for yourself, users, or other webmasters. The search bots will disregard this information.
A step-by-step guide to creating robots.txt
1. Create the robots.txt file
For this, you can use any text editor, such as notepad. If your text editor prompts you to choose the encoding when saving the file, be sure to select UTF-8.
2. Add rules for the robots
Rules are the instructions for the search bots, indicating which sections of a site can be scanned. In its guidelines, Google recommends considering the following:
- The robots.txt file includes one or multiple groups.
- Each group starts with the User-agent line. This determines which robot the rules are addressed to.
- Each group can include several directives, but one per line.
- Search engine robots process groups from top to bottom. The user agent can follow only one set of rules that is most suitable for it, which will be processed first.
- By default, the user agent is allowed to scan any pages and directories that are not blocked by the disallow rule.
- The rules are case-sensitive.
- Lines that do not match any of the directives will be ignored.
3. Upload your robots.txt file to the root directory
Once created, save your robots.txt file on the computer, then upload it to your site’s root directory and make it available to search engines.
4. Test the availability and correctness of the robots.txt file
To verify whether the file is available, you need to open your browser in incognito mode and visit https://yoursite.com/robots.txt. If you see the content and it corresponds to what you’ve specified, you can proceed with checking the correctness of directives.
You can test robots.txt with a special tool found in Google Search Console. Keep in mind that it can only be used for robots.txt files that are already available on your site.
Robots.txt templates for various CMS
If your site has a CMS, pay attention to the pages it generates, especially those that should not be indexed by search engines. To prevent this from happening, you need to close them in robots.txt. Since this is a common problem, there are file templates for sites using various popular CMS. Here are some of them.
Robots.txt for WordPress
Robots.txt for Joomla
Robots.txt for Bitrix
[fs-toc-omit]Some of the practical things you may not know about
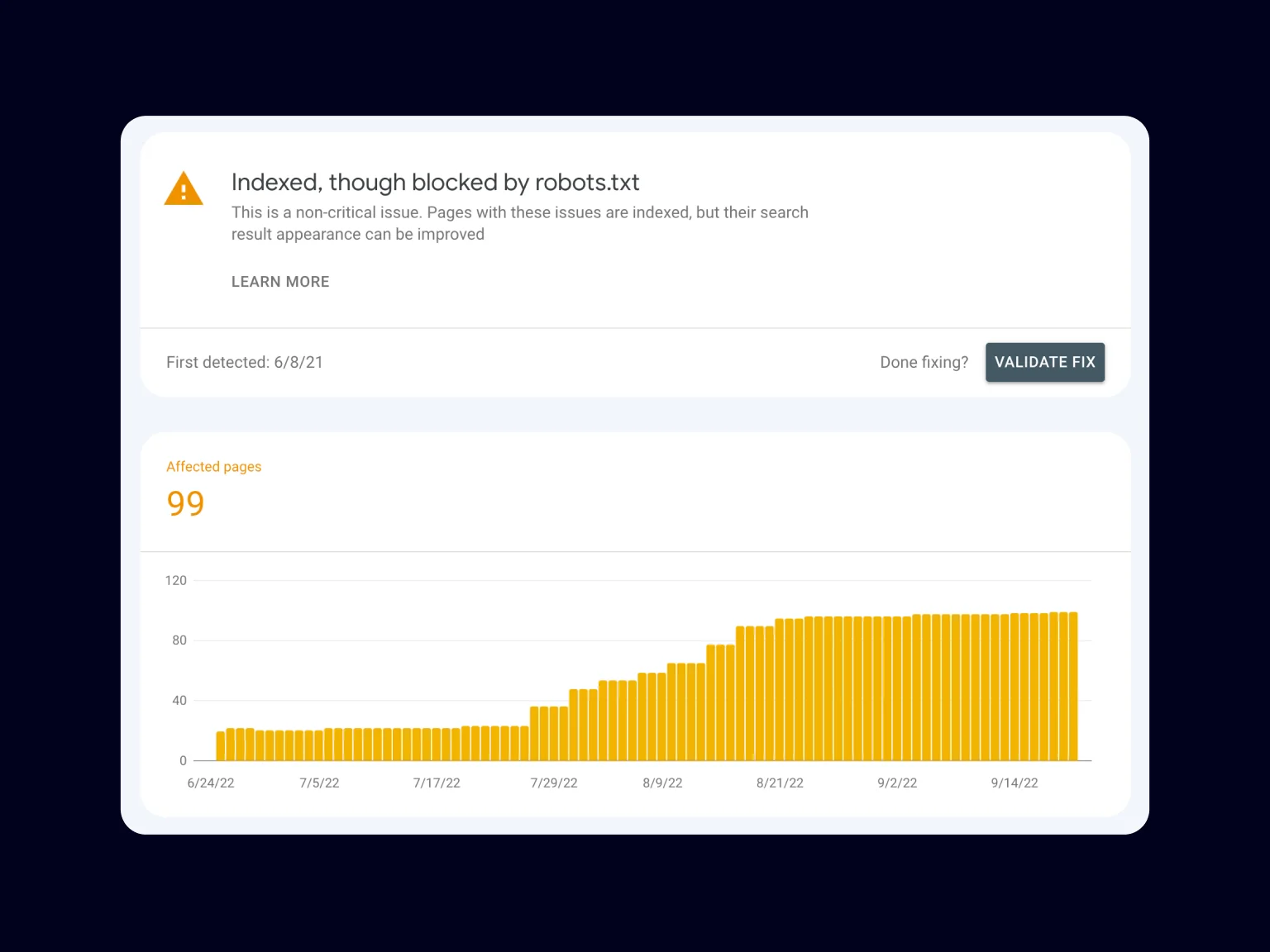
Indexed, though blocked by robots.txt
Sometimes you can see this warning in the Google Search Console. This happens when Google perceives the directives outlined in robots.txt as recommendations and not rules, thus effectively ignoring them. And although Google’s representatives do not see this as a critical problem, this, in fact, could result in a lot of junk pages being indexed.
To solve this problem, follow these recommendations:
❓ Determine whether these pages should be indexed. See what information they contain and whether they need to attract users from the search.
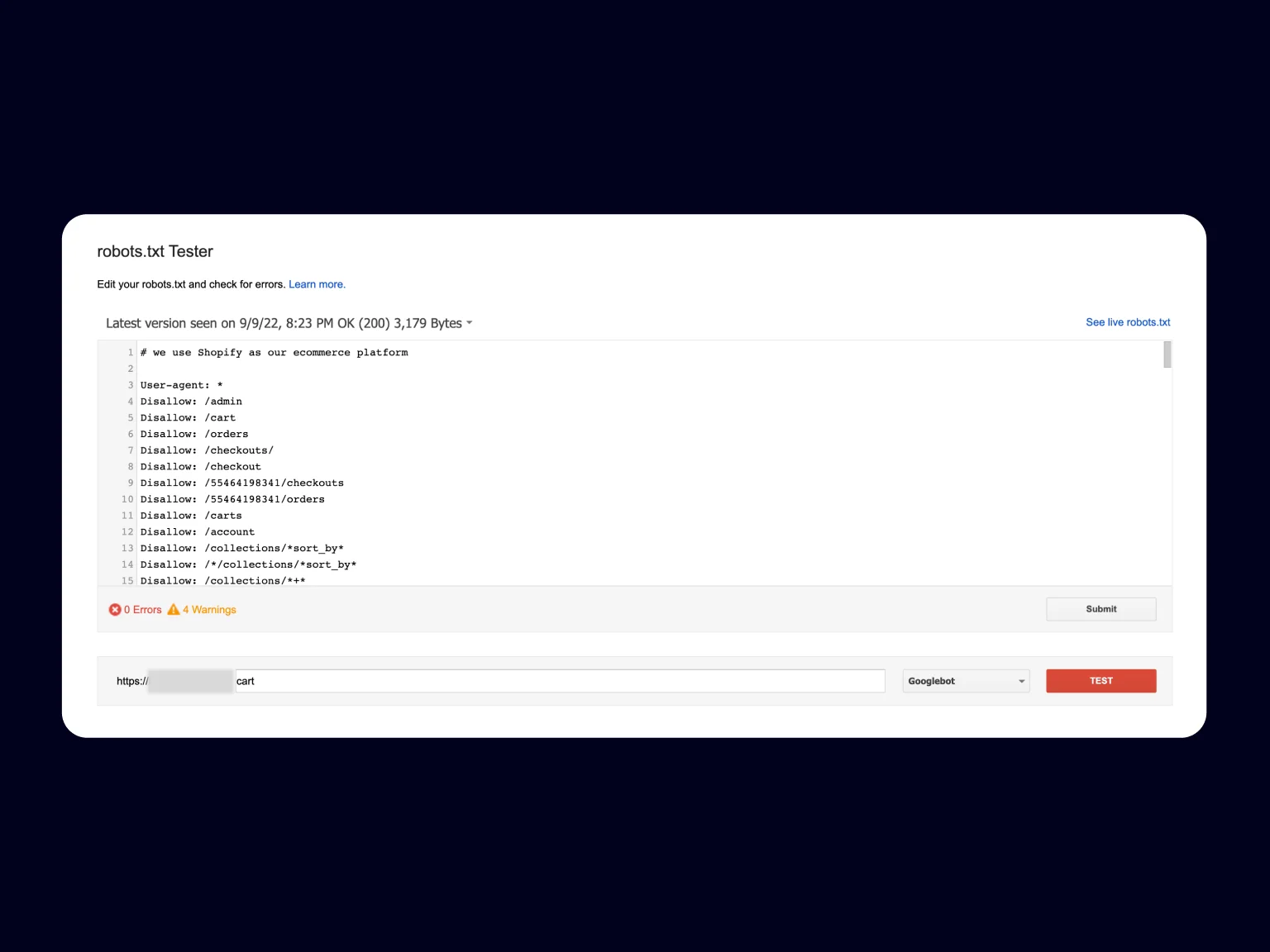
✅ If you do not want these pages blocked, find the directive responsible for this in your robots.txt file. If the answer is not apparent without third-party tools, you can do it with the robots.txt test tool.
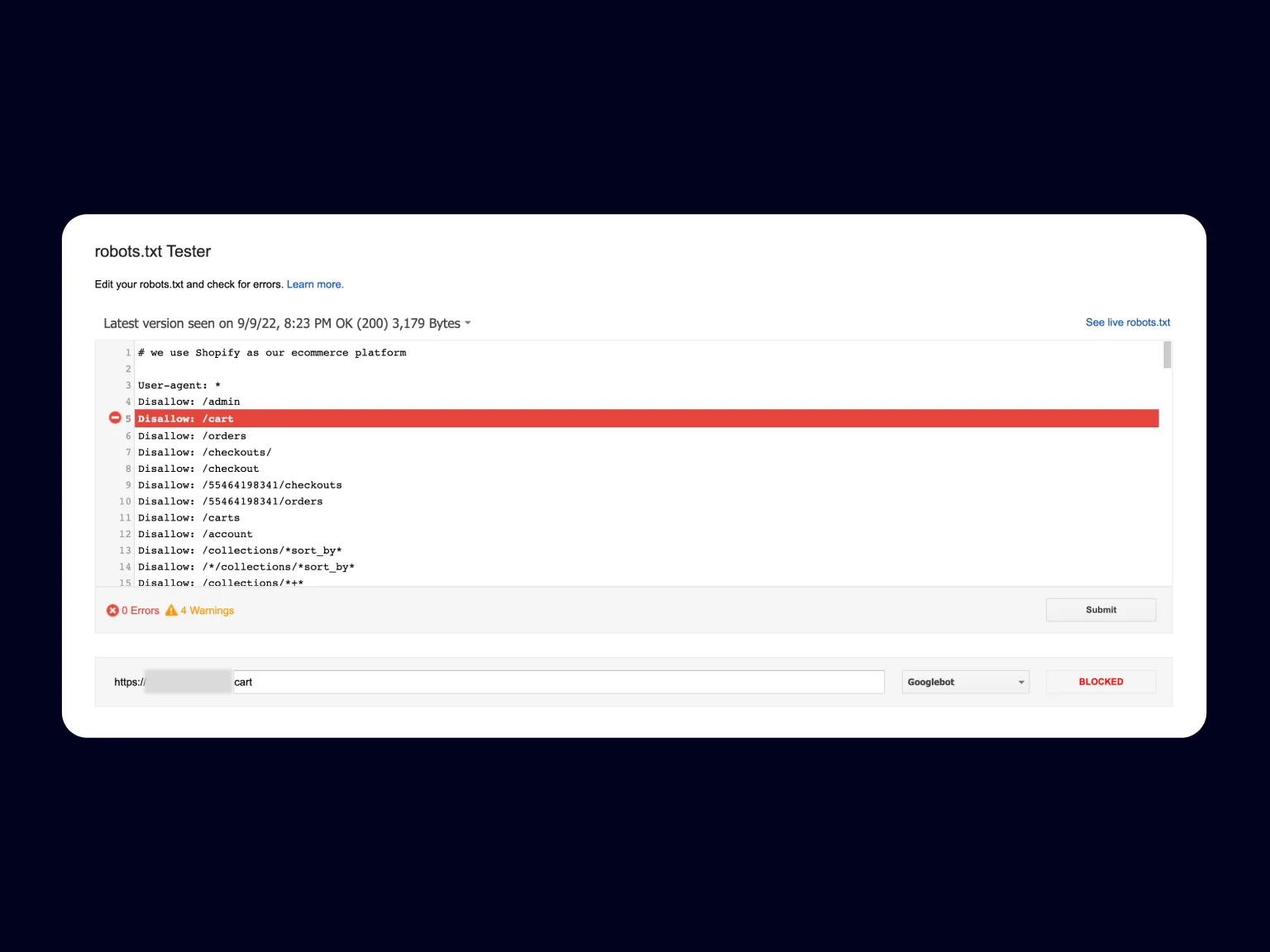
Update your robots.txt without including this directive. Alternatively, you can specify the URL you want to be indexed through Allow if you need it to hide other less useful URLs.
❌Robots.txt is not the most reliable mechanism if you want to block this page for Google search. To avoid indexing, remove the previous line used for this in the robots.txt file and add the "noindex" meta to the page.
Important! For the noindex directive to work, the robots.txt file must not block access to the page for search robots. Otherwise, the bots will not be able to process the page’s code and will not detect the noindex meta tag. As a result, this page’s content will still be visible in search results if, for instance, other sites provide links to it.
If you need to close the site for a while with 503, don’t do it for robots.txt
When a site is undergoing extensive maintenance, or there are other important reasons, you can temporarily pause or disable it, thus preventing access to both bots and users alike. For this purpose, they use the 503 server response code.
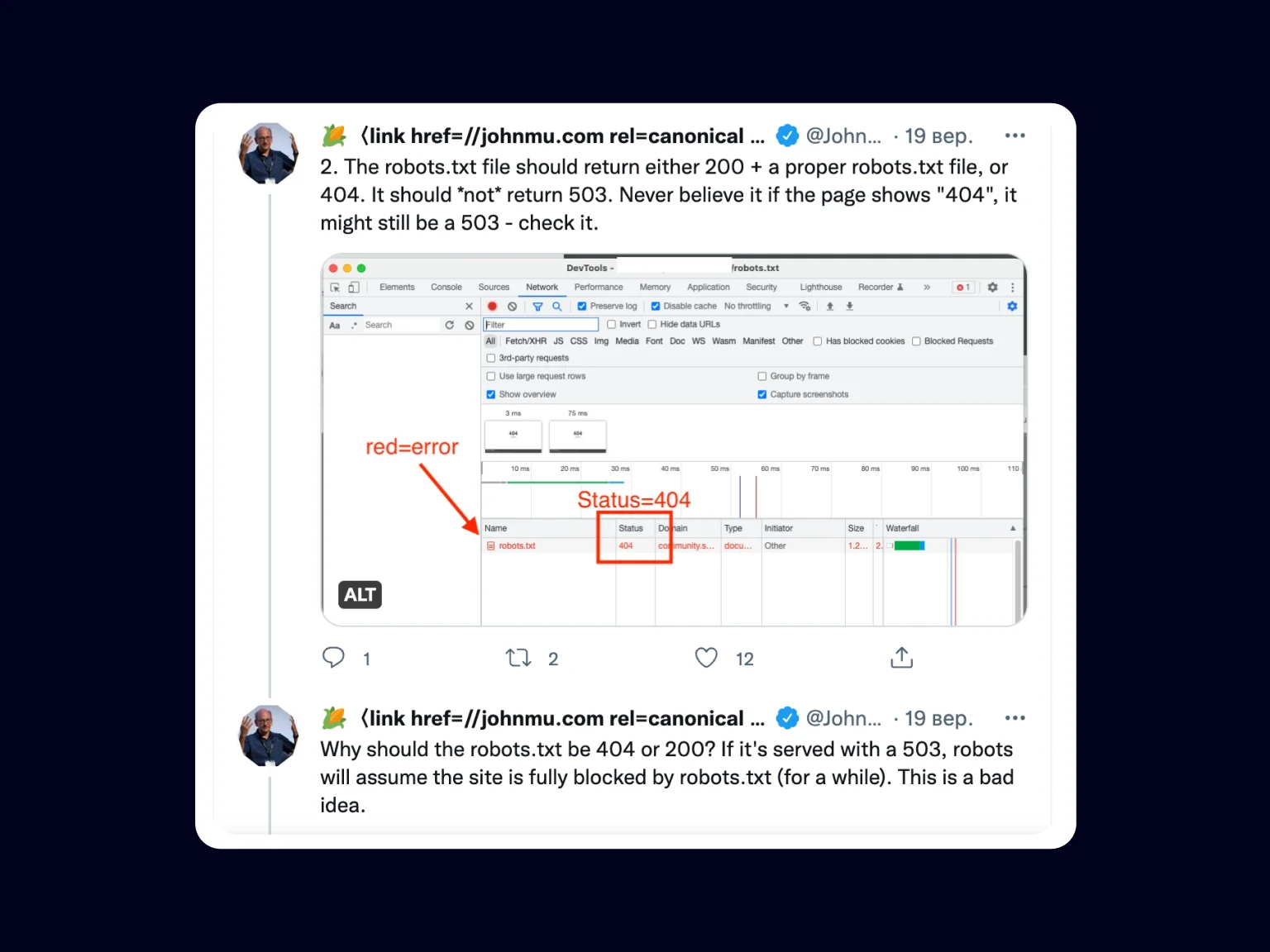
However, John Mueller, Search Advocate at Google, has shown in a Twitter thread what you need to do and check to temporarily put your site on halt.
According to John, the robots.txt file should never return a 503 because the Googlebot will assume the site is completely blocked through robots.txt. For this, the robots.txt file should return 200 OK, having all the necessary directives written in the file, or 404.
Conclusion
Robots.txt is a useful tool for shaping the interactions between search engine crawlers and your site. When used correctly, it can positively impact the site’s ranking, allowing you to manage the indexing of your documents effectively.
We hope this guide can help you understand how robots.txt files work, how they’re organized, and how to use them correctly.




.webp)



